
第四期 - 資料中心RDMA測試
資料中心RDMA測試 | 網路模擬技術分享系列第四期
前兩期資料中心模擬測試分享中,我們討論了:
- 資料中心分散式互聯測試
- 資料中心遷移測試
本期是資料中心測試三部曲的最後一期,我們將聚焦資料中心RDMA測試。
當今網際網路時代,各種線上服務如搜索、電商、直播等都需要快速地回應使用者的高頻請求。資料中心內任一環節導致的延遲,都會嚴重影響終端使用者的體驗。同時,隨著機器學習和人工智慧技術的發展,對計算能力的需求也急劇增加。為了支援日益複雜的神經網路和深度學習模型,資料中心需進行大量的分散式運算和平行通信,這可能導致通信延遲。此外,資料存儲和讀取效率的提升也至關重要。為應對這些挑戰,提高資料中心處理效率和降低網路延遲,遠端直接記憶體存取(RDMA)技術應運而生。[1]
資料中心RDMA技術
RDMA (Remote Direct Memory Access) 全稱為遠程直接記憶體存取。通過RDMA,本地端節點可以“直接”將資料通過網路發送到遠端節點的記憶體中,繞過作業系統層面的多次拷貝,實現了高輸送量、超低時延和低CPU負擔的效果。[2]
RDMA資料傳輸過程與傳統TCP/IP傳輸過程比較[3]
RDMA本身指的是一種技術。在具體協定層面,包含三種選項:
InfiniBand
2000年由IBTA (InfiniBand Trade Association) 提出的IB協議規定了一整套從網路層到傳輸層 (非傳統OSI七層模型的傳輸層,而是位於其之上) 的規範。但IB協定無法相容現有乙太網。企業如果想部署IB,除了需要購買支援IB的網卡,還要重新購買配套的交換設備,部署獨立的基礎設施[5]。
RoCE
RoCE (RDMA over Converged Ethernet) 從英文全稱可以看出它是基於乙太網網路層的協定[5]。2009年由IBTA制定。RoCE協定有v1和v2兩個版本,v1版本的網路層仍然使用了IB規範,用乙太網取代InfiniBand實體層和資料連結層。而v2使用了UDP/IP作為網路層,使得資料包也可以被路由。RoCEv2需要無損乙太網,並可在資料中心邊界內的IP網路上路由[6]。
有些觀點認為RoCE是IB的“低成本解決方案”,將IB的封包封裝成乙太網包進行收發。RoCEv2可以使用乙太網的交換設備,在企業中應用也較多[5]。
iWARP
iWARP協議是Internet Engineering Task Force (IEFT)提出的,在TCP/IP協議上提供RDMA。TCP提供流量控制和擁塞管理,不需要無損乙太網網路[6]。
TCP作為一種連線導向的可靠協議,賦予了iWARP在面對有損網路場景時 (如網路環境中經常出現丟包) 比RoCEv2和IB更高的可靠性,在大規模組網時也有明顯優勢。但大量的TCP連接會消耗很多的記憶體資源,另外TCP複雜的流量控制等機制也可能引起性能問題,導致在性能上iWARP不如基於UDP的RoCEv2和IB[5]。
下圖比較了這幾種常見RDMA技術的協定層次。

RDMA 網路通訊協定疊[6]
RDMA, 無損乙太網與網路擁塞
目前有些RDMA在乙太網上採用RoCEv2作為傳輸協議。RoCEv2採用的是基於無連線協定的UDP傳輸協定。與連線導向的TCP協議相比,UDP提供更快的傳送速率、佔用的CPU資源也更少。然而UDP協定不像TCP協定有滑動視窗、確認應答等機制來實現可靠傳輸。如果出現丟包,RoCEv2需要依靠上層應用檢測到後,再做重傳,這可能顯著影響RDMA的傳輸效率。[1]
為了充分發揮RDMA的性能,突破資料中心大規模分散式系統中的網路性能瓶頸,建立一個無丟包的無損網路環境對RDMA至關重要。而解決網路擁塞問題是實現這一目標的關鍵之一[1]。擁塞造成的負面影響主要表現在兩方面,一是使得網路處理時延增大,二是導致業務丟包,業務因為丟包重傳將進一步加劇時延,所以擁塞問題會嚴重影響計算和存儲效率[7]。
有分析指出在資料中心環境中,一個常見導致擁塞的原因是TCP Incast。TCP Incast是多對一的通信模式。當父節點向多個子節點發出資料請求,多個子節點幾乎同時向父節點回復資料,從而導致多個資料流程同時彙聚到一個節點,進而產生網路擁塞。[1]
交換機在處理微突發流量時,雖然Buffer緩衝區能夠將突發封包進行列隊等待,但由於提高Buffer容量成本較高,其效果有限。當Buffer緩衝區中的封包過多,仍會導致丟包現象。因此,為了實現端到端的無損轉發並避免因Buffer緩衝區溢位導致的丟包,交換機需要採用額外機制,例如流量控制。通過對網路流量的管理,減輕交換機Buffer的負擔,從而避免丟包問題。[1]
相關的流控和擁塞控制技術包括:PFC (Priority-based Flow Control)、 ECN (Explicit Congestion Notification)、DCQCN (Data Center Quantized Congestion Notification)、Fast ECN和HPCC (High Precision Congestion Control) 等。一些資料中心通信互聯架構的研發商,網卡廠商等也研發了相關的擁塞控制和重傳機制,比如通過基於RTT (Round Trip Timer) 及丟包統計的擁塞探測演算法,研發相關策略,實現流量快速啟動及恢復,保持交換機的低佇列深度和高輸送量。或聚焦IB協議中針對丟包場景的go-back-n機制對重傳技術做一定的修改和創新,比如進行選擇性重傳,而不是重傳丟失的資料包和所有後續資料包。[8]
在流量控制方面,這些技術聯合使用可能會更有助於達到預期效果。通過多層次,多維度的流控技術,支援RDMA網路實現低時延, 無丟包, 高吞吐的性能目標。
目前RDMA技術已經在資料中心得到廣泛應用。DPU智慧網卡廠商,支援RDMA的路由器交換機廠商,還有在這一基礎網路架構上承載的上層APP應用的業務都需要進行嚴格的測試。很多流量產生器廠商已經在儀器上集成了RoCE的協議,使得流量測試更加容易得到驗證。但RDMA在IP網路上運行,IP網路本身的不確定性仍然存在。為了充分驗證處理低時延的演算法、優化方式以及各類流控技術,仍需借助網路損傷儀器來構建模擬環境。比如在損傷環境下進行評估測試,對演算法,負載均衡,時延等進行驗證。另外儘管當前RDMA的應用主要集中在資料中心內部,但當技術擴展至跨資料中心應用,時延等其它損傷效應都會增加。因此進行RDMA的損傷測試仍是確保實現RDMA部署性能的關鍵因素。
RDMA損傷(Impairment)測試案例
損傷測試案例 1
國內某知名網路企業A,計畫在新的資料中心內部採用RDMA的技術,購買了M網卡。
但是在部署之前,企業A需要對網卡進行RDMA驗證性測試,同時需要對網卡設定參數進行評估最佳化。因此,他們在網卡之間添加了網路損傷儀器SNE,對25GbE和100GbE介面的網卡進行了添加時延,丟包,亂序等損傷測試。
測試發現,在網卡預設參數設定下,如果添加1ms的時延,業務直接從25GbE掉至2.5GbE左右, 丟包達到1%。進行25GbE介面的測試,業務直接從25GbE掉至2.5GbE左右。製造1%亂序,進行25GbE介面的測試,業務直接從25GbE掉至2.5GbE左右。
而之後通過對ACK等相關參數進行最佳化設定,發現通過一定的設定,可以大大提高其輸送量,例如:同樣添加1ms的時延,25GbE的業務可以維持在10GbE左右, 而非原先的2.5GbE。通過一系列的網路損傷測試,企業A對網卡、相關交換機的性能,以及對應網卡參數的設定進行了詳細的相容研究。這為之後部署網路提供詳細的理論和資料依據,使網路輸送量達到最佳,再結合智慧參數調配機制,可以使佈署的RDMA網路始終處於最佳的狀態。
損傷測試案例 2
國內某網卡研究機構B,對支援RoCEv2的高速網卡進行自主研發設計,對擁塞控制、重傳機制和保護機制做了創新型的研究和開發。為了驗證其演算法的相容性效果和可靠性,並將其與市場上常見的網卡進行比較,研究團隊在網卡中間加入了網路損傷儀器SNE,通過加入時延和丟包,對其網卡輸送量性能進行了驗證,與其他商業網卡相比,輸送量提升了50%到100%。研究團隊通過損傷測試對演算法參數進行了最佳化,並實際驗證了方案的可行性和可靠性。
如何進行RDMA的損傷測試?
1. 時延模擬測試
一般RDMA網路通常應用於資料中心內部網路,其中伺服器間的距離通常是幾千米到數十千米不等,但基於分散式的跨區域長距離傳輸也已經在應用,其伺服器間的距離涵蓋從上百千米到2000千米,這需要對SmartNIC/NPU/DPU/GPU等設備和產品在長距下的網路相容進行持續最佳化和測試驗證。
2. 抖動
抖動即為時延的變化,通常應用層業務會根據時延和抖動的情況,進行業務流量的調整。對於抖動,可以結合多種抖動模型進行測試,例如在固定時延上下,按照百分比抖動,高斯模型,隨機的均勻模型等。
3. 丟包
RDMA通過擁塞控制等機制來應對丟包。通常資料的重傳,會導致資料輸送量的下降,為了驗證其演算法和機制在一定丟包下,仍能達到一定的輸送量,可以通過設置不同級距的丟包比例,對業務進行研究,例如十萬分之一,萬分之一,千分之一等。
4. 亂序
丟包以後,部分封包的重傳,也會導致亂序。測試時,可以進行不同程度的亂序模擬,例如千分之一,百分之一,百分之十等級距。可以通過參數最佳化,減少亂序對於輸送量的影響。
5. 負載均衡測試
通常資料中心都有主備保護的網路,通過同時在不同線路上不同損傷參數的測試,驗證負載均衡,負載分擔的可靠性和穩定性。特別是對於含有權重的測試,真正起到模擬驗證的作用,防患於未然。
6. 疊加場景測試
真實的網路通常是由以上多種場景疊加而成,所以需要對多個維度疊加下的網路進行測試和驗證。
Calnex SNE-X 高性能高密度的網路損傷模擬器
- 介面和數量
支持8個100GbE,並且支持在一個GUI上進行多台儀器的串聯控制,構建廣大的拓撲圖。對於RDMA典型多條線路平行,以及多對一等測試場景,可以保證完整覆蓋。
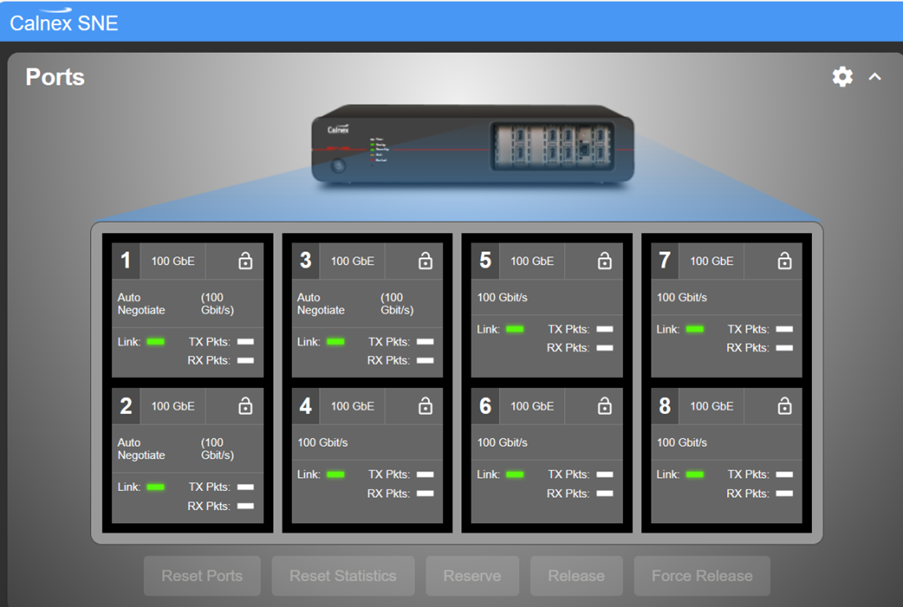 8個100GbE埠GUI介面
8個100GbE埠GUI介面
- 支援模擬時延和抖動
可以添加固定時延,添加不同模型的抖動,可以自訂抖動模型,滿足定制化演算法驗證和測試需求
 模擬時延和抖動
模擬時延和抖動
- 支援丟包模擬
可以按照比例或者隨機丟包,支援定制化丟包模型。
 模擬丟包
模擬丟包
- 支援模擬亂序
可以根據時間設定亂序深度,模擬不同程度的亂序效果。
 支援模擬亂序
支援模擬亂序
- 動態修改損傷參數設定
支援GUI上動態修改損傷參數設定,模擬現實網路動態損傷變化。
 動態修改損傷參數設定
動態修改損傷參數設定
本文參考連結及注釋:
[1] https://blog.csdn.net/yizhiniu_xuyw/article/details/126052903
[2] https://blog.csdn.net/Linuxhus/article/details/126141902
[3] https://www.51cto.com/article/648715.html
[4] https://www.h3c.com/cn/Service/Document_Software/Document_Center/Home/Switches/00-Public/Learn_Technologies/White_Paper/RDMA_Tech_White_Paper-6W100/?CHID=365286
[5] https://zhuanlan.zhihu.com/p/138874738
[6] https://www.intel.com/content/dam/www/public/us/en/documents/technology-briefs/iwarp-rdma-here-and-now-technology-brief.pdf
[7] https://zhuanlan.zhihu.com/p/642694350
[8] https://zhuanlan.zhihu.com/p/596726493
RDMA本身指的是一種技術。在具體協定層面,包含三種選項:
- IB (InfiniBand)
- RoCE (RDMA over Converged Ethernet)
- iWARP (Internet Wide Area RDMA Protocol)
InfiniBand
2000年由IBTA (InfiniBand Trade Association) 提出的IB協議規定了一整套從網路層到傳輸層 (非傳統OSI七層模型的傳輸層,而是位於其之上) 的規範。但IB協定無法相容現有乙太網。企業如果想部署IB,除了需要購買支援IB的網卡,還要重新購買配套的交換設備,部署獨立的基礎設施[5]。
RoCE
RoCE (RDMA over Converged Ethernet) 從英文全稱可以看出它是基於乙太網網路層的協定[5]。2009年由IBTA制定。RoCE協定有v1和v2兩個版本,v1版本的網路層仍然使用了IB規範,用乙太網取代InfiniBand實體層和資料連結層。而v2使用了UDP/IP作為網路層,使得資料包也可以被路由。RoCEv2需要無損乙太網,並可在資料中心邊界內的IP網路上路由[6]。
有些觀點認為RoCE是IB的“低成本解決方案”,將IB的封包封裝成乙太網包進行收發。RoCEv2可以使用乙太網的交換設備,在企業中應用也較多[5]。
iWARP
iWARP協議是Internet Engineering Task Force (IEFT)提出的,在TCP/IP協議上提供RDMA。TCP提供流量控制和擁塞管理,不需要無損乙太網網路[6]。
TCP作為一種連線導向的可靠協議,賦予了iWARP在面對有損網路場景時 (如網路環境中經常出現丟包) 比RoCEv2和IB更高的可靠性,在大規模組網時也有明顯優勢。但大量的TCP連接會消耗很多的記憶體資源,另外TCP複雜的流量控制等機制也可能引起性能問題,導致在性能上iWARP不如基於UDP的RoCEv2和IB[5]。
下圖比較了這幾種常見RDMA技術的協定層次。
RDMA 網路通訊協定疊[6]
RDMA, 無損乙太網與網路擁塞
目前有些RDMA在乙太網上採用RoCEv2作為傳輸協議。RoCEv2採用的是基於無連線協定的UDP傳輸協定。與連線導向的TCP協議相比,UDP提供更快的傳送速率、佔用的CPU資源也更少。然而UDP協定不像TCP協定有滑動視窗、確認應答等機制來實現可靠傳輸。如果出現丟包,RoCEv2需要依靠上層應用檢測到後,再做重傳,這可能顯著影響RDMA的傳輸效率。[1]
為了充分發揮RDMA的性能,突破資料中心大規模分散式系統中的網路性能瓶頸,建立一個無丟包的無損網路環境對RDMA至關重要。而解決網路擁塞問題是實現這一目標的關鍵之一[1]。擁塞造成的負面影響主要表現在兩方面,一是使得網路處理時延增大,二是導致業務丟包,業務因為丟包重傳將進一步加劇時延,所以擁塞問題會嚴重影響計算和存儲效率[7]。
有分析指出在資料中心環境中,一個常見導致擁塞的原因是TCP Incast。TCP Incast是多對一的通信模式。當父節點向多個子節點發出資料請求,多個子節點幾乎同時向父節點回復資料,從而導致多個資料流程同時彙聚到一個節點,進而產生網路擁塞。[1]
交換機在處理微突發流量時,雖然Buffer緩衝區能夠將突發封包進行列隊等待,但由於提高Buffer容量成本較高,其效果有限。當Buffer緩衝區中的封包過多,仍會導致丟包現象。因此,為了實現端到端的無損轉發並避免因Buffer緩衝區溢位導致的丟包,交換機需要採用額外機制,例如流量控制。通過對網路流量的管理,減輕交換機Buffer的負擔,從而避免丟包問題。[1]
相關的流控和擁塞控制技術包括:PFC (Priority-based Flow Control)、 ECN (Explicit Congestion Notification)、DCQCN (Data Center Quantized Congestion Notification)、Fast ECN和HPCC (High Precision Congestion Control) 等。一些資料中心通信互聯架構的研發商,網卡廠商等也研發了相關的擁塞控制和重傳機制,比如通過基於RTT (Round Trip Timer) 及丟包統計的擁塞探測演算法,研發相關策略,實現流量快速啟動及恢復,保持交換機的低佇列深度和高輸送量。或聚焦IB協議中針對丟包場景的go-back-n機制對重傳技術做一定的修改和創新,比如進行選擇性重傳,而不是重傳丟失的資料包和所有後續資料包。[8]
在流量控制方面,這些技術聯合使用可能會更有助於達到預期效果。通過多層次,多維度的流控技術,支援RDMA網路實現低時延, 無丟包, 高吞吐的性能目標。
目前RDMA技術已經在資料中心得到廣泛應用。DPU智慧網卡廠商,支援RDMA的路由器交換機廠商,還有在這一基礎網路架構上承載的上層APP應用的業務都需要進行嚴格的測試。很多流量產生器廠商已經在儀器上集成了RoCE的協議,使得流量測試更加容易得到驗證。但RDMA在IP網路上運行,IP網路本身的不確定性仍然存在。為了充分驗證處理低時延的演算法、優化方式以及各類流控技術,仍需借助網路損傷儀器來構建模擬環境。比如在損傷環境下進行評估測試,對演算法,負載均衡,時延等進行驗證。另外儘管當前RDMA的應用主要集中在資料中心內部,但當技術擴展至跨資料中心應用,時延等其它損傷效應都會增加。因此進行RDMA的損傷測試仍是確保實現RDMA部署性能的關鍵因素。
RDMA損傷(Impairment)測試案例
損傷測試案例 1
國內某知名網路企業A,計畫在新的資料中心內部採用RDMA的技術,購買了M網卡。
但是在部署之前,企業A需要對網卡進行RDMA驗證性測試,同時需要對網卡設定參數進行評估最佳化。因此,他們在網卡之間添加了網路損傷儀器SNE,對25GbE和100GbE介面的網卡進行了添加時延,丟包,亂序等損傷測試。
測試發現,在網卡預設參數設定下,如果添加1ms的時延,業務直接從25GbE掉至2.5GbE左右, 丟包達到1%。進行25GbE介面的測試,業務直接從25GbE掉至2.5GbE左右。製造1%亂序,進行25GbE介面的測試,業務直接從25GbE掉至2.5GbE左右。
而之後通過對ACK等相關參數進行最佳化設定,發現通過一定的設定,可以大大提高其輸送量,例如:同樣添加1ms的時延,25GbE的業務可以維持在10GbE左右, 而非原先的2.5GbE。通過一系列的網路損傷測試,企業A對網卡、相關交換機的性能,以及對應網卡參數的設定進行了詳細的相容研究。這為之後部署網路提供詳細的理論和資料依據,使網路輸送量達到最佳,再結合智慧參數調配機制,可以使佈署的RDMA網路始終處於最佳的狀態。
損傷測試案例 2
國內某網卡研究機構B,對支援RoCEv2的高速網卡進行自主研發設計,對擁塞控制、重傳機制和保護機制做了創新型的研究和開發。為了驗證其演算法的相容性效果和可靠性,並將其與市場上常見的網卡進行比較,研究團隊在網卡中間加入了網路損傷儀器SNE,通過加入時延和丟包,對其網卡輸送量性能進行了驗證,與其他商業網卡相比,輸送量提升了50%到100%。研究團隊通過損傷測試對演算法參數進行了最佳化,並實際驗證了方案的可行性和可靠性。
如何進行RDMA的損傷測試?
1. 時延模擬測試
一般RDMA網路通常應用於資料中心內部網路,其中伺服器間的距離通常是幾千米到數十千米不等,但基於分散式的跨區域長距離傳輸也已經在應用,其伺服器間的距離涵蓋從上百千米到2000千米,這需要對SmartNIC/NPU/DPU/GPU等設備和產品在長距下的網路相容進行持續最佳化和測試驗證。
2. 抖動
抖動即為時延的變化,通常應用層業務會根據時延和抖動的情況,進行業務流量的調整。對於抖動,可以結合多種抖動模型進行測試,例如在固定時延上下,按照百分比抖動,高斯模型,隨機的均勻模型等。
3. 丟包
RDMA通過擁塞控制等機制來應對丟包。通常資料的重傳,會導致資料輸送量的下降,為了驗證其演算法和機制在一定丟包下,仍能達到一定的輸送量,可以通過設置不同級距的丟包比例,對業務進行研究,例如十萬分之一,萬分之一,千分之一等。
4. 亂序
丟包以後,部分封包的重傳,也會導致亂序。測試時,可以進行不同程度的亂序模擬,例如千分之一,百分之一,百分之十等級距。可以通過參數最佳化,減少亂序對於輸送量的影響。
5. 負載均衡測試
通常資料中心都有主備保護的網路,通過同時在不同線路上不同損傷參數的測試,驗證負載均衡,負載分擔的可靠性和穩定性。特別是對於含有權重的測試,真正起到模擬驗證的作用,防患於未然。
6. 疊加場景測試
真實的網路通常是由以上多種場景疊加而成,所以需要對多個維度疊加下的網路進行測試和驗證。
Calnex SNE-X 高性能高密度的網路損傷模擬器
- 介面和數量
支持8個100GbE,並且支持在一個GUI上進行多台儀器的串聯控制,構建廣大的拓撲圖。對於RDMA典型多條線路平行,以及多對一等測試場景,可以保證完整覆蓋。
8個100GbE埠GUI介面- 支援模擬時延和抖動
可以添加固定時延,添加不同模型的抖動,可以自訂抖動模型,滿足定制化演算法驗證和測試需求
模擬時延和抖動- 支援丟包模擬
可以按照比例或者隨機丟包,支援定制化丟包模型。
模擬丟包- 支援模擬亂序
可以根據時間設定亂序深度,模擬不同程度的亂序效果。
支援模擬亂序- 動態修改損傷參數設定
支援GUI上動態修改損傷參數設定,模擬現實網路動態損傷變化。
動態修改損傷參數設定本文參考連結及注釋:
[1] https://blog.csdn.net/yizhiniu_xuyw/article/details/126052903
[2] https://blog.csdn.net/Linuxhus/article/details/126141902
[3] https://www.51cto.com/article/648715.html
[4] https://www.h3c.com/cn/Service/Document_Software/Document_Center/Home/Switches/00-Public/Learn_Technologies/White_Paper/RDMA_Tech_White_Paper-6W100/?CHID=365286
[5] https://zhuanlan.zhihu.com/p/138874738
[6] https://www.intel.com/content/dam/www/public/us/en/documents/technology-briefs/iwarp-rdma-here-and-now-technology-brief.pdf
[7] https://zhuanlan.zhihu.com/p/642694350
[8] https://zhuanlan.zhihu.com/p/596726493